B-Tree: Self-Balancing Engine Of Modern Database
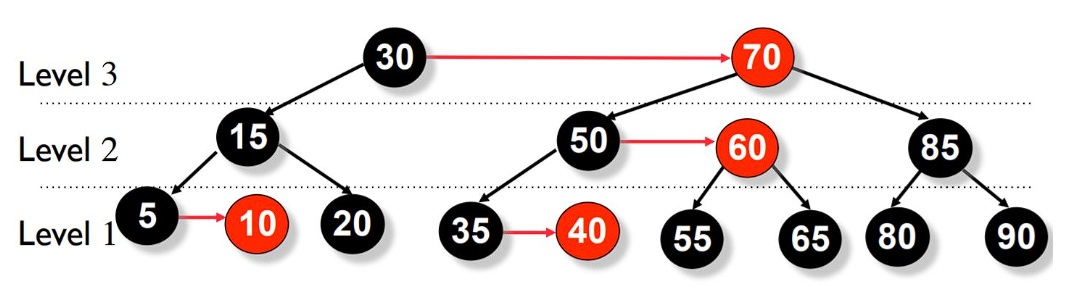
In our previous deep dive into the m-Way Search Tree, we discovered how increasing the order $m$ flattens the tree, reducing its height. However, the pure m-Way Tree has a fatal algorithmic flaw: it lacks a self-balancing mechanism. In the worst-case scenario of sequential insertions, it degrades into a linear linked list, resulting in $O(n)$ access time.
To power robust, large-scale systems like relational databases (MySQL, PostgreSQL) and file systems (NTFS, ext4), we need a structure that strictly enforces balance regardless of insertion order. Enter the B-Tree - a self-balancing m-Way Search Tree optimized for systems that read and write large blocks of data.
1. Why does B-Tree rule the Disk?
To truly understand B-Tree, we must step away from abstract mathematics and look at hardware physics. Main memory (RAM) is fast, but secondary storage (HDD or SDD) is comparatively slow.
Storage devices read and write data in fixed-sized blocks called Pages (often 4KB or 8KB). Accessing a single byte on a disk fetching the entire page into RAM. This operation is astronomically expensive in terms of CPU cycles.
A B-Tree mitigates this by aggressively expanding horizontally. By setting the order $m$ such that the size of one B-Tree node perfectly matches the size of one disk page, we ensure that traversing one step down the tree requires exactly one disk access. A B-Tree of order $m = 1000$ containing a billion keys might only have a height of 3. That means finding any record among a billion requires a maximum of 3 disk reads.
2. Mathematical anatomy of a B-Tree
Properties of a B-Tree
A B-Tree of order $m$ is a highly constrained m-Way Search Tree. To guarantee structural balance ($O(\log m)$ time complexity), it must satisfy strict mathematical invariants:
- Root Constraint: The root must have at least 2 children (unless it is a leaf).
- Node Capacity Limits:
- Every node has at most $m$ children and $m-1$ keys.
- Every internal node (except the root) must be at least half-full. It must have at least $\lceil m/2 \rceil$ children and $\lceil m/2 \rceil - 1$ keys.
- Perfect Leaf Alignment: All leaf nodes must exist strictly at the exact same level. This property is what defines it as “perfectly balanced”.
Following is an example of a B-Tree of order 4:
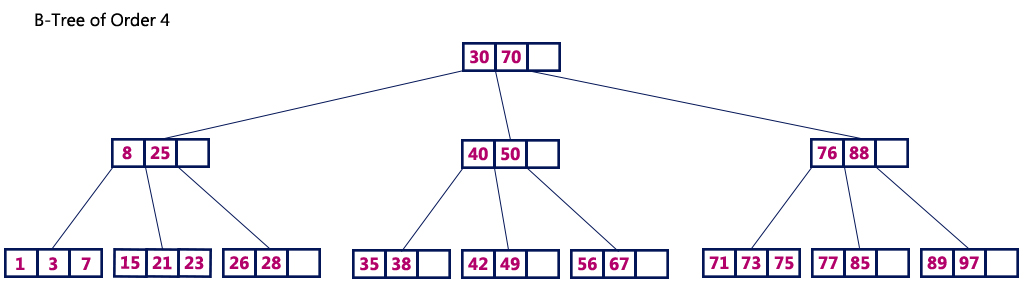
We can see in the above diagram that all the leaf nodes are at the same level and all non-leaf nodes have no empty sub-tree and have number of keys one less than the number of their children.
B-Tree’s Height theorems
The absolute guarantee of a B-Tree’s performance lies in its height bounds. Let $n$ be the total number of keys in a B-Tree of order $m$ and height $h$ (assuming the root is at level 1). Let the minimum degree be $t = \lceil m/2 \rceil$.
- Minimum Height: The tree is as flat as possible when every node is completely saturated with $m - 1$ keys. The height is bounded by:
- Maximum Height: The tree is as tall as possible when every internal node contains the bare minimum of keys ($t - 1$). By summing the nodes at each level, mathematicians have proven the upper bound:
These theorems mathematically prove that the height grows logarithmically.
Complexity analysis
Define a B-Tree
From a C++ low-level perspective, we must modify our previous mWayNode by introducing a boolean flag to identify leaf status, which dictates our traversal and splitiing logic:
1
2
3
4
5
6
7
#define M 4
struct BTreeNode {
int count; // Current number of keys
int keys[M - 1]; // Array of sorted keys
BTreeNode* children[M]; // Array of pointers to subtrees
bool isleaf; // True if node is a leaf
};
3. Operation in B-Tree
Searching
Searching in a B-Tree is a two-tier process that beautifully balances fast CPU operations with slow Disk I/O.
When looking for a target key $X$, starting from the root:
- In-Memory Binary Search: Once a node (a disk page) is loaded into RAM, we perform a standard Binary Search within its sorted
keysarray. Because this happens entirely in the CPU cache, it is blindingly fast. - Evaluation:
- If $X$ matches a key, the search terminates successfully.
- If $X$ is not found, the binary search gives us the correct routing index $i$ where $k_{i-1} < X < k_i$.
- Disk Traversal: We look at the pointer $P_i$. If the current node’s
isleafflag istrue, the pointer isnullptrand the key does not exist. Otherwise, we command the hardware to fetch the child node $P_i$ from the disk into RAM, and recursively repeat the process.
Insertion
Unlike a Binary Search Tree that growns downwards, a B-Tree growns upwards.
When inserting a new key $X$:
- Traverse down to the appropriate leaf node.
- If the leaf is not full, insert $X$ into the array.
- The Split: If the leaf is full (an overflow condition), we temporarily insert $X$ to find the median key. The node is violently split into two halves.
- Promotion: The median key is stricly pushed up to the parent node. If the parent is also full, the split cascades upwards. If the root splits, a new root is created, increasing the height by 1.
Deletion
Deletion might cause a node to fall below its minimum threshold. This triggers an underflow state.
The rescue operation has two phase:
- Borrowing: The deficient node looks to its immediate sibling. If a sibling has spare keys, we perform a rotation: pull a key from the sibling up to the parent, and pull the parent’s separating key down.
- Merging: If both siblings are at minimum capacity, we merge the deficient node, its sibling, and the separating key from the parent into a single node. This removes a key from parent, potentially causing the parent to underflow, cascading the deletion upwards.