m-Way Tree
In previous explorations of data structures, we heavily relied on the binary paradigm - where a node makes a strict binary decision (left or right). However, as data volumes scale, especially in disk-based storage systems, the height of a binary search tree becomes a bottleneck. To minimize the number of memory accesses, we must flatten the tree. This bring us to the generalization of the binary search tree: the m-Way Search Tree.
1. What is an m-Way Tree?
An m-Way Search Tree is a tree structure where $m$ represents the “order” of the tree. Unlike a binary tree where a node holds exactly one key and two child pointers, a node in an m-Way tree can hold up to $m-1$ keys and route to $m$ child pointers.
To define it strictly mathematically, an m-Way Search Tree of order $m$ must satisfy these properties:
- Each node has at most $m$ children.
- Each node contains a maximum of $m-1$ keys, sorted in strictly ascending order: $k_1 < k_2 < \dots < k_{count}$.
- For any given key $k_i$ in a node:
- All keys in the child subtree $T_i$ (to the left of $k_i$) are strictly less than $k_i$.
- All keys in the child subtree $T_{i+1}$ (to the right of $k_i$) are strictly greater than $k_i$.
So, why do we need m-Way Search Tree? To understand the why the m-Way Tree is heavily utilized in large-scale databases, we must analyze its discrete mathematical bounds. The cost of any retrieval, insertion, or deletion operation is directly proportional to the height of the tree, requiring $O(h)$ node accesses. Therefore, our primary algorithmic goal is to minimize $h$.
Given an m-Way Search Tree of height $h$ containing $n$ elements (keys):
- Element Bounds: The total number of elements range from a minimum of $h$ (a degenerate tree degrading into a linked list with 1 key per node) to a maximum of $m^h-1$ (a perfectly saturated tree when every node is completely full):
\(h \le n \le m^h - 1\)
- Height Bounds: Conversely, for a given dataset of $n$ elements, the height $h$ is mathematically bounded by:
By increasing the order $m$, we effectively flatten the structure. This ensure the height $h$ remains as close to the optimal logarithmic bound $\log_m(n+1)$ as possible, drastically reducing the $O(h)$ memory access operations compared to a standard binary tree.
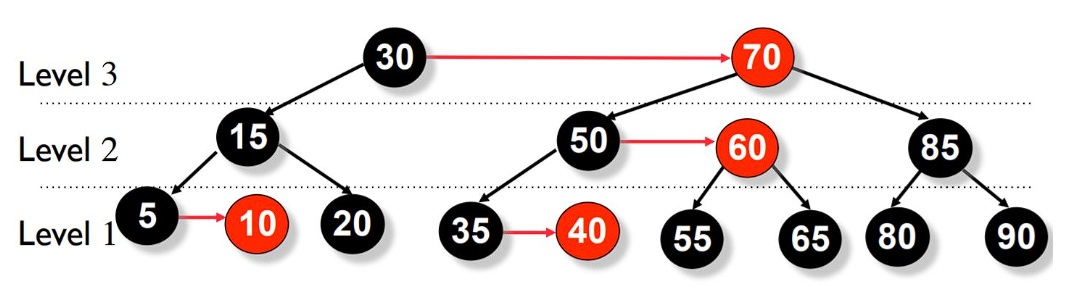
An example of a 4-Way Search Tree is shown in the figure below. Observe how each node has at most 4 child nodes and therefore has at most 3 keys contained in it.
From a low-level systems perspective, we can represent an m-Way node in C++ using manual memory allocation and arrays rather than abstract objects:
1
2
3
4
5
6
7
8
#include <iostream>
#define M 4 //Define the order of the tree (e.g., a 4-Way Tree)
struct Node {
int count; //Current number of keys in this node
int key[M - 1]; //Array holding up to M - 1 sorted keys
Node* child[M]; //Array of raw pointers to M children
};
This contiguous array layout significantly improves CPU cache locality compared to scattered binary nodes.
2. Searching
The search operation in an m-Way Tree is a generalized form of the binary search. When looking for a target value $X$, we perform a local search within the current node’s keys array.
Since the keys are sorted, we can linearly scan (or binary search) the array to find the first key $k_i$ such that $X \le k_i$.
- If $X == k_i$, the search terminates successfully.
- If $X < k_i$, we recursively traverse down the pointer $P_i$.
- If we exhaust the array and $X$ is greater than the last key, we traverse down the rightmost pointer $T_{count+1}$.
If we hit a nullptr during traversal, the key does not exist in the tree. The maximum time complexity is bounded by $O(h \cdot m)$, where $h$ is the height of the tree.
Here is the source code of search operation using C++ pointers:
1
2
3
4
5
6
7
Node* search(Node* root, int val, int* pos) {
if (root == nullptr) return nullptr;
if (searchNode(root, val, pos))
return root;
else
return search(root->child[*pos])
}
3. Insertion
Inserting a new key into a standard m-Way Search Tree mimics the binary search tree approach: all new keys are initially placed in the leaf node.
The algorithm operates as follows:
- Traverse: Use the search logic to traverse down the tree until a leaf node is reached.
- Check capacity:
- If the leaf node has space (current
count< $m-1$), we shift the existing larger keys one position to the right to maintain order, and insert the new key. - If the leaf node is completely full (
count== $m-1$), we must dynamically allocate a newNode. We link this new node as a child of the current leaf and insert the key there.
- If the leaf node has space (current
Unlike self-balancing structures like B-Trees, a pure m-Way Search Tree does not split nodes or balance itself during insertion. This lack of self-balancing means it can be degrade into a linked list in the worst case if keys are inserted sequentially.
4. Deletion
Deletion is the most complex operation, as it requires careful manipulation of the array elements and memory pointers. We divide delete into main scenarios based on the node’s location:
Scenario A: The key is in a Leaf Node
This is straightforward. We simply locate the key, remove it, and shift all subsequent keys in the array one step to the left to fill the memory gap. Finally, we decrement the count variable.
Scenario B: The key is in a Internal Node
We cannot simply remove a key from an internal node without breaking the structural routing mechanism of the tree. Instead, we must replace it:
- Find the In-order Predecessor (the largest key in the left subtree $T_i$) or the In-order Successor (the smallest key in the right subtree $T_i+1$).
- Copy the value of this predecessor/successor into the target key’s position in the internal node.
- Recursively call the delete function to remove that predecessor/successor from its originial leaf node.